But, although these are the most common operations, they do not in and of themselves satisfy all the requirements for a data system. One significant advantage of an object-based data system is that new operations can be added at any time. One simply builds a "method" which takes as its input information that supplied by one (or more) objects rather than data files, transforms the information in some way, and passes it on to the user application.
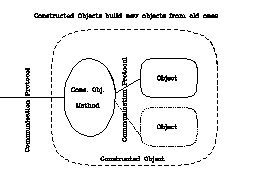
We call the combination of the new method and the sub-objects a "constructed object." You can also think of these as similar to UNIX filters. For example, we can add a column to the /test (hydrographic data) which gives a linearized estimate of density:
rho=28.5-0.2 T +0.7 (S-35)
by using the ``math'' constructed object which takes as parameters an input object name and formulae for changing/ adding columns. The new object name is
math(/test,rho=28.5-0.2*temp+0.7*(sal-35))
and this can be used by the lister/plotter/... in exactly the same way as any other object --- see figure.
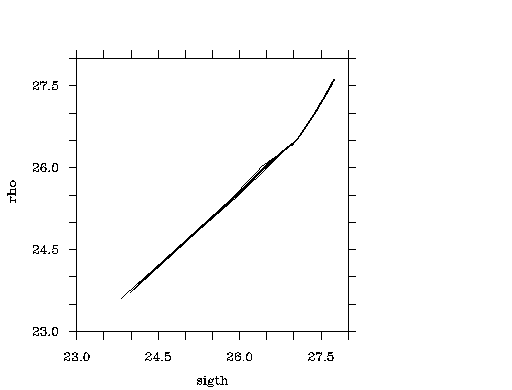
As another example, there is a plot from two data objects joined together by common station, cast, and pressure.
join(/tco2,/poc(station,cast,press,poc))